Terminology
- $s_{t}$ = state - 일반적으로 markovian state로 가정함, 현재 시스템의 설정을 표현한 것 (ex. 좌표, velocity 등)
- $o_{t}$ = observation - input
- $a_{t}$ = action - output
- $\pi_{\theta}\left ( a_{t}\mid o_{t} \right )$ = policy - input에서 output으로 가기 위한 중간과정
- $\pi_{\theta}\left ( a_{t}\mid s_{t} \right )$ - policy (fully observed) - 더 제한적인 특별한 케이스

Imitation Learning
- 사람에게서 추출한 $o_{t}$와 $s_{t}$를 사용함
- Behavioral Cloning (줄여서 BC)라고 하기도 함
일반적으로 Imitation Learning은 제대로 돌아가지 않음
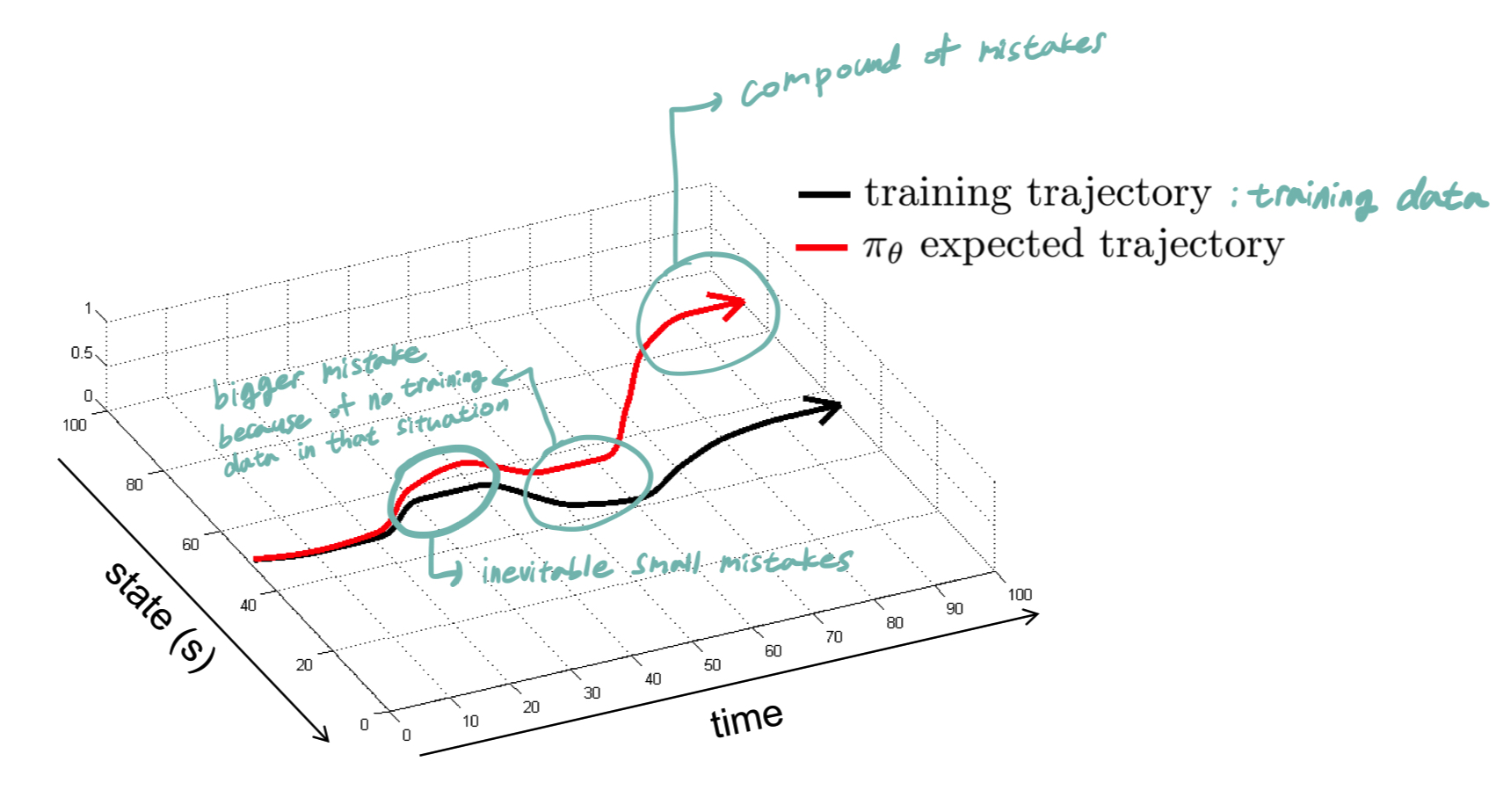
그 이유는
1. 어떤 경우에든 작은 실수를 할 수 있음
2. 그 작은 실수를 한 경우에 어떻게 해야할지 모르기 때문에 더 큰 실수를 하게 됨
3. 결과적으로 그러한 실수들이 합쳐져서 전혀 다른 결과가 나옴
의 과정을 거치기 때문이다. ( = distributional "drift")
제대로 동작하게하기 위해서는 많은 학습데이터와 약간의 트릭들을 사용하면 된다.
하지만 그럼에도 오류가 발생할 수 있는데 제대로 동작하는 확률을 높이려면 $p_{data}\left ( o_{t} \right ) = p_{\pi_{\theta}}\left(o_{t}\right)$를 만족하게 하면 된다.
(여기서 $p_{data}\left ( o_{t} \right )$는 data distribution, 즉 데이터 분포를 의미한다)
--> DAgger
DAgger
- Dataset Aggregation
- $p_{data}\left ( o_{t} \right ) = p_{\pi_{\theta}}\left(o_{t}\right)$를 만드는 것이 가능할지
- $p_{\pi_{\theta}}\left(o_{t}\right)$를 똑똑하게 만들기보다 $p_{data}\left ( o_{t} \right )$를 똑똑하게 만들면 된다
--> 목표: $p_{data}\left ( o_{t} \right )$가 아니라 $p_{\pi_{\theta}}\left(o_{t}\right)$에서 데이터를 수집한다.
- $p_{\pi_{\theta}}\left(o_{t}\right)$를 똑똑하게 만들기보다 $p_{data}\left ( o_{t} \right )$를 똑똑하게 만들면 된다
1. $\pi_{\theta}\left (a_{t} \mid o_{t}\right )$를 사람에 의해 수집된 데이터인 $D = \{o_{1}, a_{1}, ... , o_{N}, a_{N}\}$으로 학습한다.
2. $\pi_{\theta}\left (a_{t} \mid o_{t}\right )$를 실행해서 데이터셋 $D_{\pi} = \{o_{1}, ... , o_{M}\}$을 얻는다.
3. 사람이 직접 $D_{\pi}$에 맞는 action은 $a_{t}$를 label한다.
4. 두 데이터, $D$와 $D_{\pi}$를 합친다: $D \leftarrow D \cup D_{pi}$
다시 1번으로 돌아가서 반복한다.
문제점: 3번 process
1) 사람이 계속 새로 추출된 데이터에 직접 label을 붙여야 한다.
2) 사람이 올바른 action을 알지 못하는 경우도 있다.
Expert와 똑같이 행동하지 못하는 이유
사람의 행동은
1. Non-Markovian behavior이다.
- 사람은 과거의 경험을 토대로 행동을 결정하기도 하기 때문에 과거를 아예 신경쓰지 않는 것은 자연스럽지 않다.
- 하지만 과거 경험을 모델에 모두 적용시키려고하면 너무 많은 weights가 생겨버린다.
- 개선 방안
- 각각의 frame을 CNN으로 학습하고 그 과거의 결과들을 RNN으로 학습한다. (주로 LSTM 이용)
- 하지만 잘못된 것 계속해서 학습할 수 있어 제대로 동작하지 않을 수 있다.
- 개선 방안
2. Multimodal behavior이다.
- 사람은 왼쪽으로 이동했다가, 오른쪽으로 이동했다가 하는 등 결정을 하는데 여러가지가 영향을 미친다. 따라서 같은 상황에서도 다양한 행동을 한다.
- 개선 방안
- Output Mixture of Gaussians
- 가장 단순한 방법
- 최종 action을 뽑을 때 하나의 Gaussian값만 가지고 고려하는 것이 아니라 여러 Gaussian 값들을 모두 고려한다.
- 문제: dimension이 많고 복잡한 모델에서는 적용하기 힘들다
- dimension이 클수록 지수함수로 mixture gaussians 양이 많아지기 때문
- Latent variable models
- 가장 복잡하지만 가장 표현력이 좋음
- action은 single gaussian을 가지고 결정되지만, input을 할 때 latent variable(= noise)을 모델에 집어넣는다.
- 더 자세한 것은 아래의 것들을 살펴보면 좋다.
- Conditional variational autoencoder
- Normalizing flow/realNVP
- Stein variational gradient descent
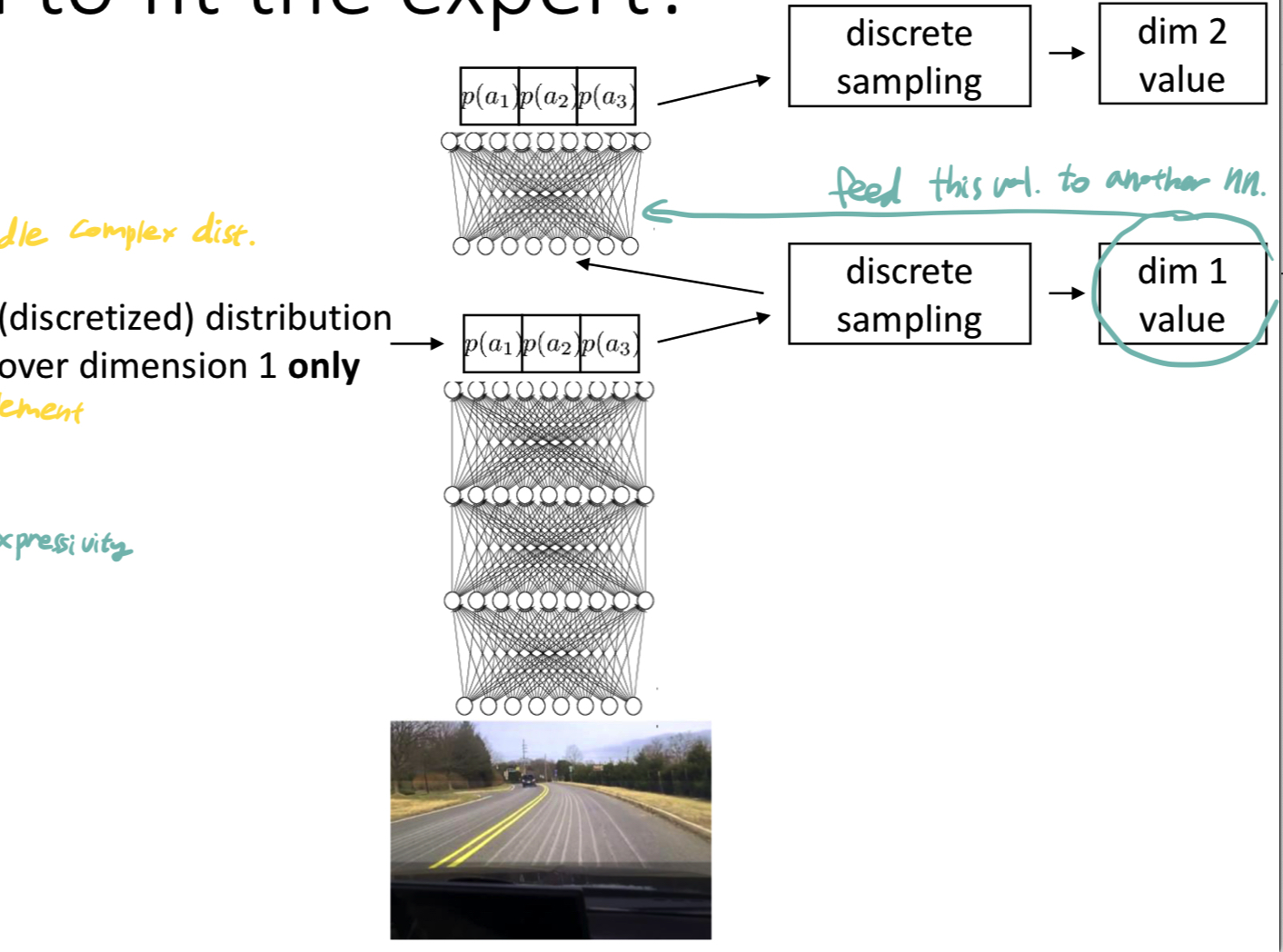
- Autoregressive discretization
- 표현력이 어느정도 좋으면서 구현하기 엄청 복잡하지는 않다.
- 한 번에 하나의 dimension에 대한 discrete를 뽑아낸다. 이렇게 만들어진 dim value를 다시 네트워크의 입력으로 넣어주는 것을 반복한다.
- Output Mixture of Gaussians
- 개선 방안
Cost Functioin for Imitation
reward와 cost function을 정의해서 action에 대한 평가를 진행한다.
reward function: $r\left( s, a \right) = \log p\left( a = \pi^{*}\left(s\right) \mid s\right)$
- 더 실용적인 선택
- 선택한 action의 로그 확률이 $\pi^{*}\left(s\right)$(= unknown policy)와 같다.
cost function: $c\left(s,a\right) = \begin{cases}0 \space if \space a = \pi^{*}\left(s\right)\\1 \space otherwise\end{cases}$
- 0: unknown policy가 완벽하게 expert와 매치함
- 1: 매치하지 않음
0, 1 loss는 이론적인 분석을 할 때 편리하고, 실수의 수를 직접적으로 셀 수 있음
그 후 강의에서 supervised learning이 실수할 확률이 $\epsilon$보다 작다고 가정한 후 분석을 진행했는데 Big-O가 $O\left(\epsilon T^{2}\right)$가 나왔다 --> 비효율적
어쩌다 발견했는데 아래 블로그가 굉장히 정리를 잘해주셨다.
영상보고 이해 안가면 이거 참고해도 될 듯
https://leejunhyun.github.io/deep%20learning/2018/09/03/CS294-02/
[CS294] Lecture 2 : Supervised Learning and Imitation
UC Berkeley의 강화학습 강의 CS294(2018 Fall semester)를 정리한 포스트입니다.
leejunhyun.github.io
'Study Log > Software Engineering' 카테고리의 다른 글
| [삽질기록] Conda ResolvePackageNotFound 에러 (feat. environment.yml) (1) | 2023.02.08 |
|---|---|
| PyTorch 공부 (부제: Simplified MobileNet 구현) (1) | 2022.12.05 |
| 01. OT (0) | 2022.11.15 |
| pm2와 관련된 것들 (0) | 2022.10.12 |
| [삽질기록] RDS 연결 안됨 (0) | 2022.10.11 |




댓글